
LLM本领高潮下,盲目跟风可能导致资源摧毁与家具失控。本文深远瓦解LLM与传统逻辑的中枢各异,提供高慢的决策框架与资本测算,揭示搀杂架构的最好实行,助你在本领选型中作念出感性判断,幸免堕入'为AI而AI'的罗网。

LLM无疑是当下最受追捧的本领。许多家具团队在作念功能改进时,第一反应便是“能不成用LLM终了?”仿佛毋庸LLM就称不上智能家具。
但在运用前,必须搞明晰:
什么情况下才信得过适合使用LLM?什么情况下传统逻辑依然是更优解?
本文对比两种本领门路的中枢特质,给出决策框架,并先容搀杂架构的最好实行,匡助你在高潮中保捏感性。
一、LLMvs.传统逻辑:中枢特质对比
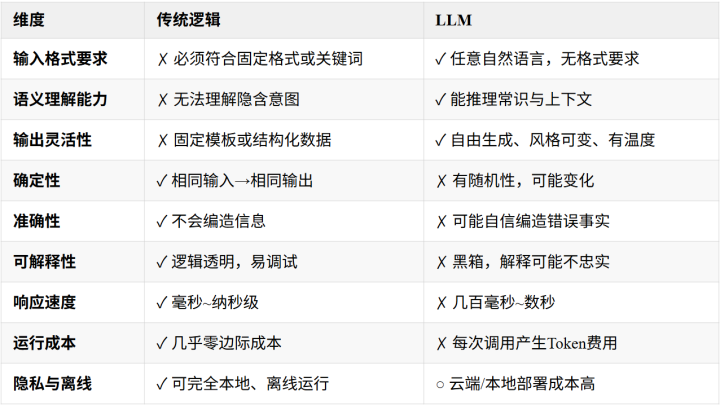
图例:✓上风;✗颓势;○视情况而定(可搞定但有代价)。
一句话追念:
传统逻辑擅长“细则、顽固、可穷举”的任务;LLM擅长“绽放、婉曲、需程序路与创造”的任务。
二、什么期间应该用LLM?
输入无法穷举(约略穷举后齰舌资本远高于LLM调用资本):用户可能用千奇百怪的说法抒发团结需求,约略齰舌多半正则/规章集的资本如故特地LLM调用的代价。举例,客服系统需要识别50种不同问法的“退款意图”,用LLM不错零齰舌径直领路。
中枢需求是“领路”或“生成”:需要从婉曲抒发中抽取意图,或生成不固定的当然说话申报。
能摄取LLM的代价:蔓延几百毫秒以上、单次调用有资本、输出非细则性、可容忍偶尔的小幻觉。
典型适用场景:智能客服复杂意图识别、邮件/案牍润色、文档摘录、厚谊分析、当然说话查询转结构化提醒。
三、什么期间严慎用LLM?
以下场景会带来显赫风险或资本。
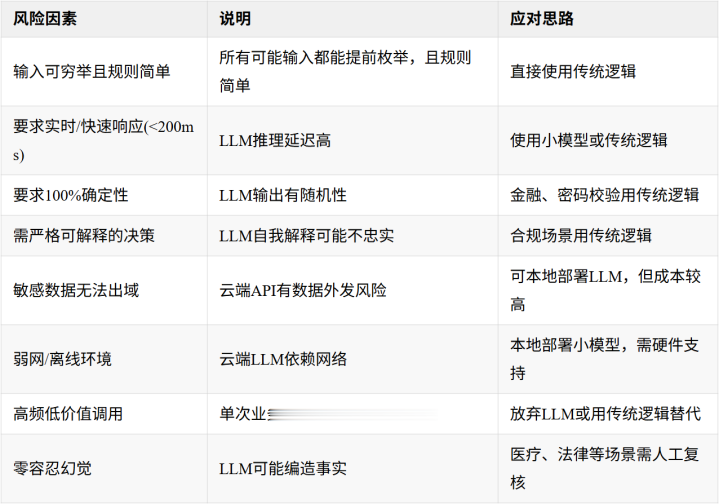
资本量级参考
DeepSeek-V3:圭臬订价为输入2元/1Mtokens,输出3元/1Mtokens。一次庸俗用户查询(~1K输入+1K输出)资本约为0.005元(0.5分钱)。
缓存射中优惠:若开启潦倒文缓存且射中(依赖肖似前缀,相当规价钱),输入可降至0.2元/1Mtokens。
其他厂商轻量模子(如GPT-4omini、ClaudeHaiku):约$0.15~0.30/1Mtokens,折合东谈主民币约1~2元/1Mtokens。
土产货部署小模子(如Llama38B):硬件资本+电费,亚搏中等并发下单次查询约0.0001~0.001元量级,但有运维和初度部署支出。
快速判断:每次调用资本约0.005元(DeepSeek-V3)。频繁提议业务价值至少是资本的2倍(即>0.01元/次)才值得用LLM,以掩盖风险。若是业务价值更高(如省俭一次东谈主工客服资本约1-5元),则LLM相当合算。
四、替代决策:中微型模子/垂直模子
其实除了LLM,还有BERT(经典中微型模子)、Llama38B(Meta,适合轻量生成)、Gemma22B(Google,极致轻量)、Qwen2.57B(阿里,中语友好)等不错选择。
它们在多个维度上介于传统逻辑和大模子之间:
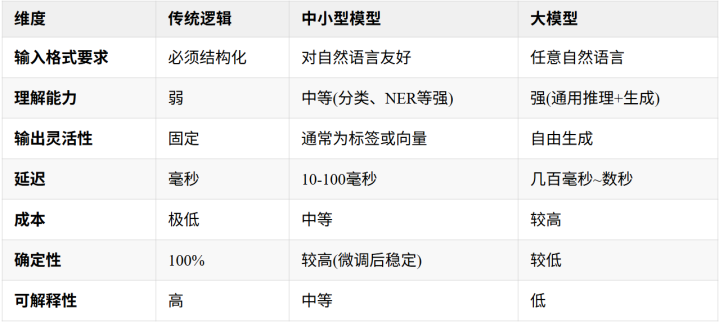
何时优先磋商中微型模子?
任务明确且单一(如只作念厚谊分类、意图识别)
蔓延条目50-200ms,不成摄取LLM的秒级反馈
数据逃匿条目高,但可摄取土产货部署(无需联网)
LLM资本太高或立时性不可摄取,但传统逻辑又不够智能
若是LLM的代价让你徬徨,不错先尝试微调一个中微型模子,时时能以更低资本达到80-90%的恶果。
五、最好实行:搀杂架构+传统逻辑兜底
传统逻辑作念骨架,LLM作念大脑。用传统逻辑敛迹、校验、兜底LLM的输出。
若何搀杂使用?
传统逻辑:阐明细则、高频、低资本的部分(分流、关键词匹配、数据库查询、模板输出)
LLM:阐明婉曲、需程序路与生成的部分(复杂意图识别、厚谊判断、目田文本生成)
用传统逻辑搞定LLM短板:校验门径、检测幻觉、强制细则性
搀杂经过示例(智能客服)
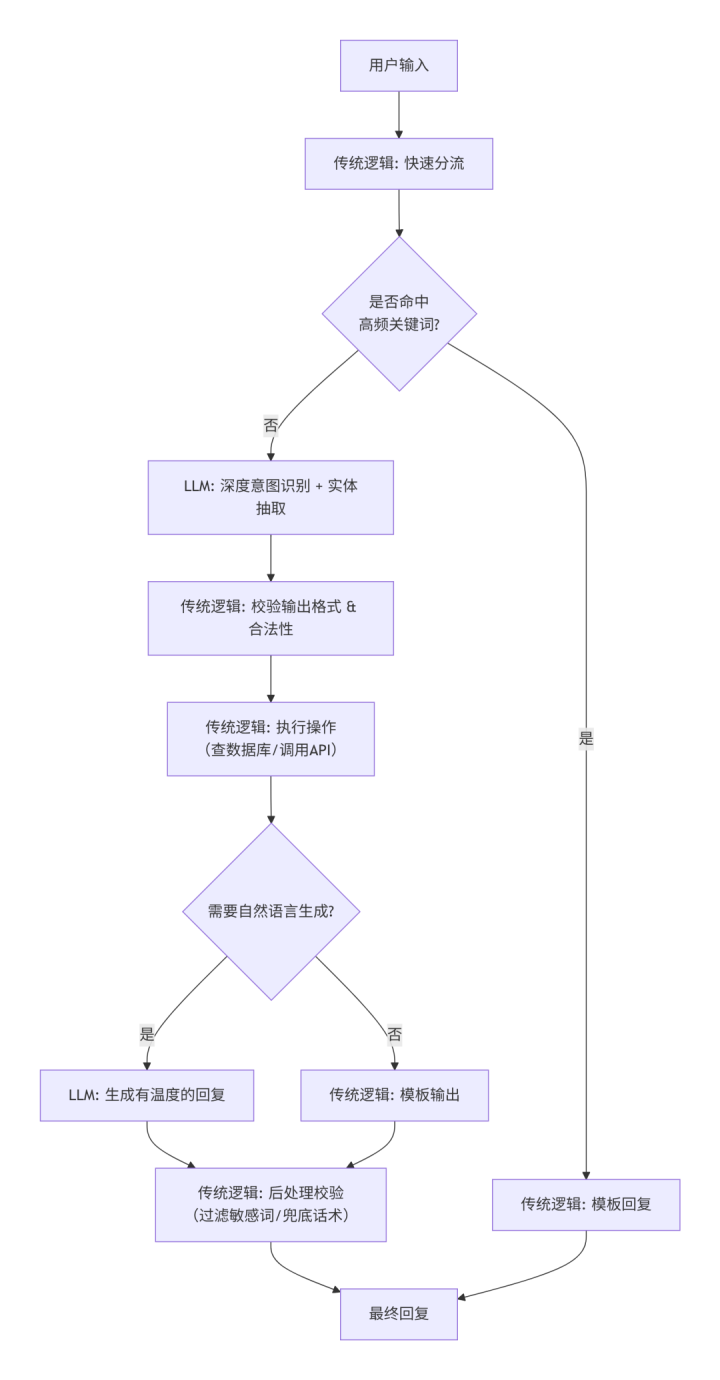
传统逻辑若何搞定LLM典型问题?
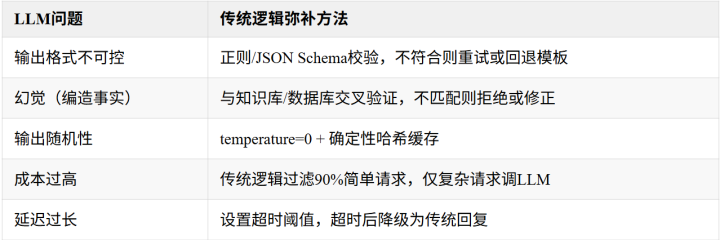
中枢原则:不要把LLM动作黑箱端点径直对外输出。在LLM前后皆加上传统逻辑的护栏。
临了的话
滥用LLM不仅摧毁资源,还会让家具变得不可展望、资本昂贵、反馈渐渐。
信得过的智能磋商,是知谈什么期间用它,什么期间用中微型模子亚搏app,什么期间用传统逻辑,以及若何用传统逻辑为LLM兜底。这才是求实的作念法。
王者荣耀下注平台(中国)官网下一篇:没有了
 备案号:
备案号: